Hello everyone! So this article will be on how you can create your own Docker registry hub and push your own Docker images to it. So before we start, here are the prerequisites. They're obvious, but let's make sure.
My Deployment Process - BTS (Behind The Scenes)
Posted on April 17, 2024527 views13 min read
Alright so I've made a video in the past on how I do my deployments, but I've never really went into details on what is actually going on and how it actually works. So in this article, I'll do a deep dive on this subject. There won't be any code samples in this article. It's just going to mostly be a wall of text for an article so let's get into it.
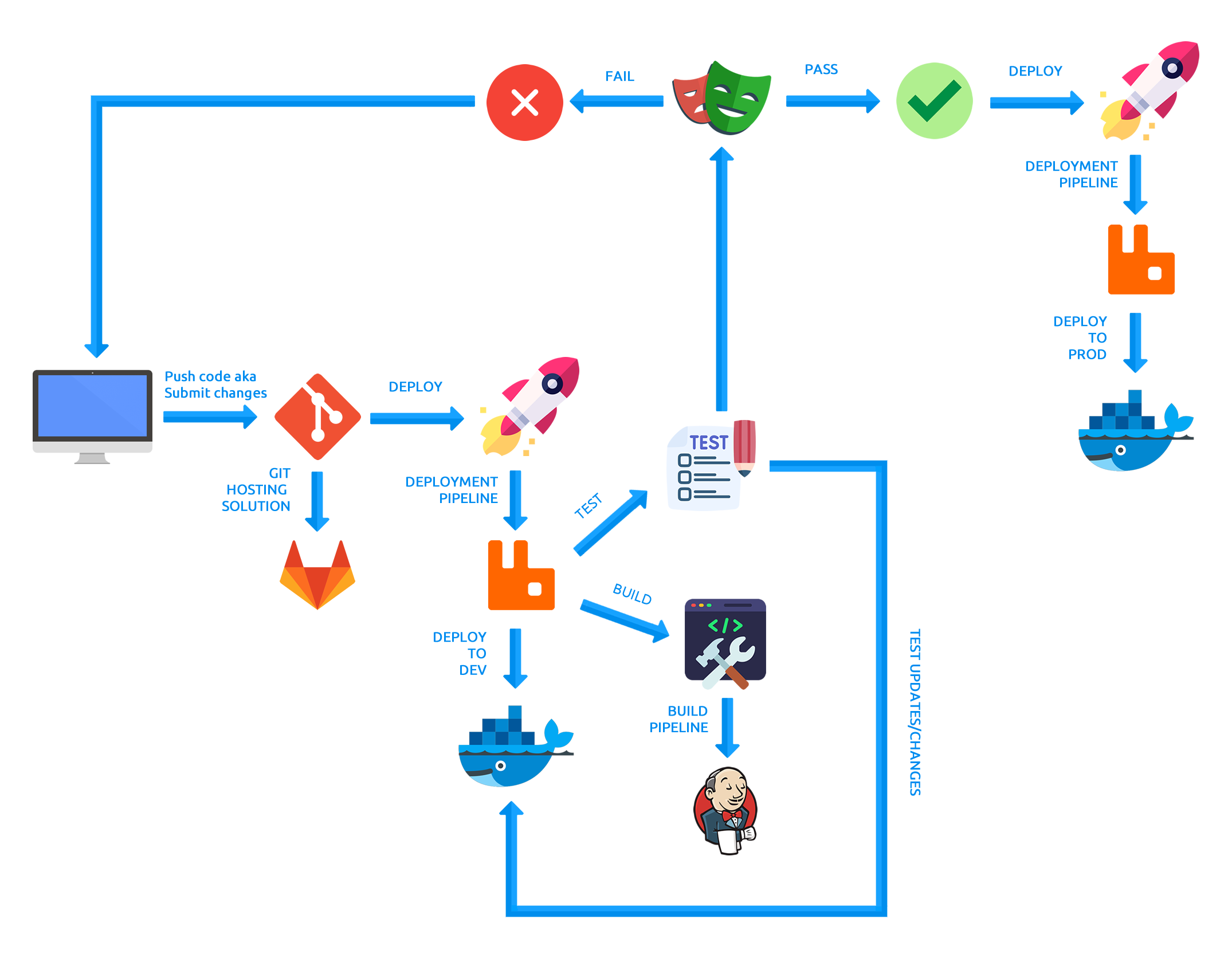
So first things first. I have created the image above to illustrate my deployment cycle as much as possible. I don't own the icons and I don't claim ownership. I just took them off the internet and created the image.
Technologies That Are Used In This Process
- Git (Version control technology)
- Gitlab (Git hosting solution)
- RabbitMQ (Queuing system)
- Docker (Containerization technology)
- Jenkins (Build pipeline)
- Playwright (UI testing tool)
- PHP (Programming language)
So with that being said, let's dive into the image a little more. Starting from the left hand side, I start the cycle by having a local development area. I tend to try and mimic what's out there in PROD (production/final release) such as; the programming language that's being used including similar version numbers, database type e.g. MySQL, configuration files, operating system, etc. When you mimic your PROD server, if you ever run into any issues, bugs or errors most likely your development environment or your other environments will have the same issues or relative issues. It's not 100% accurate, but it's very reliable since you can test your application against the same operating system and the same configurations and you'll most likely get very similar results.
So once I have my local environment setup, I tend to develop on it first. If I like the code I currently have locally, what I'll tend to do is I'll do what's called a "commit". This involves having Git installed and having my local project or application attached to a Git repository. A Git repository is pretty much just a "project" if you will that uses the Git technology and holds all of your code and files in there.
To dummy this down, a "commit" is pretty much a snapshot in time of your current changes. When you create a "commit", these "commits" are stored as hashes (sha1) in your Git repo. Essentially, it allows you to have what's called "version control" or "version history". This means anything you change is tracked. This is a good thing because if you ever break a piece of code, you can revert those changes. You can also look back at how your codes and files were structured from the very beginning. You can also do what's called a "clone" which is pretty much copying down the repository onto whatever device you want and work on your project from anywhere. This is what's really neat and cool about the Git technology. It's very powerful and it allows the ability to also collaborate with other people.
So moving forward. Once I submit my code changes to my local Git repository, I'll then do what's called a "push" to my Gitlab server that's running in a Docker container. Gitlab is a hosting solution for Git and it's pretty much just a UI that allows you to do a lot of things with Git. Gitlab is completely free and you can easily install it. It's pretty much a freemium product. There are some parts of Gitlab that's a paid service, but majority of it is free. I'll create an article on how to install Gitlab through Docker in a future article.
Now, pushing my code changes to Gitlab isn't my "final" step. What actually happens during this process is that it triggers a bunch of processes. This is what I call my "deployment pipeline". During this process, Gitlab actually sends a POST request with a JSON object that holds the entire "commit" including which project it's coming from, what branch it's on, the filenames of those changes, etc to my RabbitMQ container. RabbitMQ is a queuing system that allows you to send events to it and every time you do so, it queues up those events and consumes the messages. I chose to go with RabbitMQ for a couple of reasons which I created a video a while back on, but I'll sort of repeat it here as well.
- When Gitlab sends those JSON objects to RabbitMQ through the sender, it will queue up in the system.
- This allows me to keep those "commits" so as long as they aren't consumed yet.
- The reason why I want that kind of behavior is in case there is ever a network connectivity issue.
- This means if the messages aren't consumed yet during the process, the "deployment pipeline" can restart from the beginning in case the PROD site is in a "broken" state.
- The message is only consumed at the very end of the receiver once the receiver has completed its tasks.
So with that being said, the receiver is what actually kicks off a bunch of processes depending on the condition that's being met. Below are the conditions.
- Is this commit coming from the master branch? - If yes then deploy the current code that's in the master branch (always the final set of codes) to the PROD server. - If no then check to see if it's coming from the develop branch. - Is the commit from the develop branch? - If yes then - deploy the current code that's in the develop branch to the DEV (develop) Docker container - If the deployment is finished then kick off the Playwright test against the current DEV (develop) Docker container - deploy the current code that's in the develop branch to the Jenkins server for that particular project's develop branch on the Jenkins server - If no then it's coming from a feature or different branch and the commit will be ignored.During this process, commits that are coming from the master branch will always be a "merge request". This means that it is the "final step" in this deployment pipeline. The first step is actually from the develop branch. Commits coming from the develop branch will run in those conditions. Both the Playwright test results and the builds from the develop branch on the Jenkins server will be returned and posted on the specific "commit" hash in Gitlab. If both pass then a "merge request" can be allowed. If either 1 of those are returned as a "failed" result, then the "merge request" cannot be allowed and any "merge request" submitted will be rejected until both are returned as passed.
This is a fail safe in case code breaking changes were implemented. The Playwright tests will reflect this if a piece of code is broken or doesn't function the way it's supposed to and fail out. When a failed result is returned from the Playwright tests, I will then have to go back and determine what caused the Playwright tests to fail and if I can incorporate a new way or revert the changes back. Sometimes though the Playwright tests do return false positives and it's just a simple assertion count mismatch or a timeout due to server connectivity. In which case the tests are re-ran and upon passes, the failed "commit" will then be promoted and merged into master. The Playwright tests are always tested against the DEV (develop) container. The DEV (develop) container will always have "new code" as this is the branch that gets promoted to when a local change is pushed to the Gitlab server. This DEV (develop) container is isolated and is only accessible at a VPN level whereas the PROD server is accessible publicly through the internet.
The deployment pipeline between deploys from either develop or master is always automated by the RabbitMQ receiver. Once a "commit" on the Gitlab server has been detected, the deployment process starts to occur.
My deployment process is pretty different from how a lot of people and companies run their deployment process. Some companies use Ansible and Kubernetes to do their deployments. Some use AWS. I don't intend to use those tools since I have created my own homegrown deployment pipeline which really works for me. This pipeline allows me to ship my code directly to my PROD server and that's what I like.
Where PHP plays into all of this is that the sender, the receiver, and the operation in which the Playwright tests get kicked off and results sent back to the Gitlab server are all written in PHP. The sender and receiver deals with RabbitMQ and the deployment process. The operation behind the Playwright stuff that uses PHP deals with the database which updates the results including which specific Playwright tests ran on which specific "commit". PHP is heavily used in majority of my projects which again is my main language.
Currently, my Jenkins server acts as 2 things. It acts as another repository hub which stores the current workspace aka repository and it also deploys my container images to my personal private Docker registry hub I created. The Docker registry technology itself can be installed from the official Docker hub however the UI behind displaying those container images is a homegrown UI built using PHP. This allows me to create and publish Docker images to my private registry hub and it also allows me to pull those images down to my local machine to then create my own local containers based off of those images.
That's all I have for the Behind The Scenes. Hopefully you enjoyed reading this article and have a better understanding of how my deployment pipeline works.